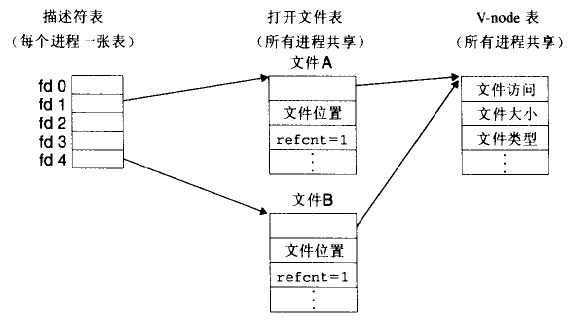
搞懂递归
什么是递归
周末你带着女朋友去电影院看电影,女朋友问你,咱们现在坐在第几排啊?电影院里面太黑了,看不清,没法数,现在你怎么办?
别忘了你是程序员,这个可难不倒你,递归就开始排上用场了。于是你就问前面一排的人他是第几排,你想只要在他的数字上加一,就知道自己在哪一排了。但是,前面的人也看不清啊,所以他也问他前面的人。就这样一排一排往前问,直到问到第一排的人,说我在第一排,然后再这样一排一排再把数字传回来。直到你前面的人告诉你他在哪一排,于是你就知道答案了。
这就是一个非常标准的递归求解问题的分解过程,去的过程叫“递”,回来的过程叫“归”。基本上,所有的递归问题都可以用递推公式来表示。刚刚这个生活中的例子,我们用递推公式将它表示出来就是这样的:
1 | f(n)=f(n-1)+1 其中,f(1)=1 |