分布式锁 在分布式系统中,如何保证多个进程或线程之间对共享资源的访问互斥性和并发性?
如何保证多个进程或线程之间的互斥性和并发性? 在一个分布式系统中,多个进程或线程需要对共享资源进行读写操作,如果不加限制,可能会导致数据不一致或者出现竞态条件。因此,需要引入分布式锁来控制对共享资源的访问。
MySQL实现分布式锁的一种常见方式是使用InnoDB的行级锁和SELECT … FOR UPDATE语句。简单,使用方便,不需要引入Redis、zookeeper等中间件。但不适合高并发的场景,db操作性能较差,没有设置超时时间,有锁表的风险。具体步骤如下:
创建一个名为mutex的表,该表只有一个名为name的列,用于存储锁的名称。例如:
1 2 3 4 5 CREATE TABLE mutex (name varchar (128 ) NOT NULL , PRIMARY KEY (name)) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4; INSERT INTO `mutex`(`name`) VALUES ('my_lock_name' );
当需要获取锁时,使用SELECT … FOR UPDATE语句查询mutex表中对应的行,并在事务中执行该语句。例如:
1 2 3 4 5 START TRANSACTION; SELECT name FROM mutex WHERE name = 'my_lock_name' FOR UPDATE ;COMMIT ;
当不再需要锁时,使用DELETE语句将mutex表中对应的行删除。例如:
1 DELETE FROM mutex WHERE name = 'my_lock_name' ;
另外一种方式,0或者没有这行数据,代表没有持有锁,非0代表存储的锁具体持有锁的对象,需要实现一个定时器,定时检测锁超时,需要自己主动定时检测,锁是否释放。
速度慢
锁超时不方便
锁释放通知不方便
高可用的方案比较少(分布式关系型数据库tidb)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 DROP TABLE IF EXISTS `dislock`;CREATE TABLE `dislock` ( `id` int (11 ) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键' , `lock_type` varchar (64 ) NOT NULL COMMENT '锁类型' , `owner_id` varchar (255 ) NOT NULL COMMENT '持锁对象' , `count` int (11 ) NOT NULL COMMENT '计数器' , `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP , PRIMARY KEY (`id`), UNIQUE `idx_lock_type` (`lock_type`) ) ENGINE= InnoDB AUTO_INCREMENT= 1 DEFAULT CHARSET= utf8 COMMENT= '分布式锁表' ; INSERT INTO dislock(`lock_type`, `owner_id`, `count`) VALUES ('activity_test' , '3245jk' , 0 );delete from dislock where `lock_type` = 'activity_test' and `owner_id` = '3245jk' ;update dislock set count = count + 1 where `lock_type` = 'activity_test' and `owner_id` = '3245jk' ;
MySQL的乐观锁可以使用版本号或时间戳来实现。具体步骤如下:
在需要应用乐观锁的表中新增一个版本号或时间戳字段。例如,新增一个名为version的整型字段。
当需要更新一条记录时,在UPDATE语句中将版本号加1(或将时间戳更新为当前时间),并且WHERE条件中加入版本号等于原始值的判断。例如: 1 2 3 4 5 6 7 8 9 CREATE TABLE `mylock` ( `id` int (11 ) unsigned NOT NULL AUTO_INCREMENT COMMENT '' , `value ` varchar (64 ) NOT NULL COMMENT '' , `version` int (11 ) NOT NULL COMMENT '' , PRIMARY KEY (`id`) ) ENGINE= InnoDB AUTO_INCREMENT= 1 DEFAULT CHARSET= utf8 COMMENT= '' ; INSERT INTO `mylock` (`id`, `value `, `version`) VALUES (1 , 'test' , 456 );UPDATE `mylock` SET `value ` = 'new_value' , `version` = `version` + 1 WHERE `id` = 1 AND `version` = 456 ;< !
如果使用时间戳来实现乐观锁,则需要在更新时将时间戳更新为当前时间,而不是加1。例如: 1 2 UPDATE `table_name` SET `column1` = 'new_value' , `timestamp_column` = CURRENT_TIMESTAMP () WHERE `id` = 123 AND `timestamp_column` = 'original_timestamp' ;< !
需要注意的是,使用乐观锁时需要避免长事务和慢查询等问题,以确保锁的释放和事务的快速执行。
可以使用ZooKeeper等分布式协调服务来实现分布式锁。如果有很多的客户端频繁的申请加锁、释放锁,对于Zookeeper集群的压力会比较大。性能不如redis实现的分布式锁。
为了确保公平,可以简单的规定:编号最小的那个节点,表示获得了锁。所以,每个线程在尝试占用锁之前,首先判断自己是排号是不是当前最小,如果是,则获取锁。
Zookeeper的节点Znode有四种类型:
持久节点:默认的节点类型。创建节点的客户端与zookeeper断开连接后,该节点依旧存在。
持久节点顺序节点:所谓顺序节点,就是在创建节点时,Zookeeper根据创建的时间顺序给该节点名称进行编号,持久节点顺序节点就是有顺序的持久节点。
临时节点:和持久节点相反,当创建节点的客户端与zookeeper断开连接后,临时节点会被删除。
临时顺序节点:有顺序的临时节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 class DistributedLock {public : DistributedLock (const std::string& lock_path, const std::string& node_path); ~DistributedLock (); bool lock () bool unlock () private : std::shared_ptr<zookeeper_handle_t > zk_handle_; std::string lock_path_; std::string node_path_; }; DistributedLock::DistributedLock (const std::string& lock_path, const std::string& node_path) : lock_path_ (lock_path), node_path_ (node_path) { zk_handle_ = std::make_shared <zookeeper_handle_t >(); zookeeper_init (zk_handle_.get (), NULL , 0 , NULL , NULL , 0 ); zoo_create (zk_handle_.get (), lock_path_.c_str (), nullptr , -1 , &ZOO_OPEN_ACL_UNSAFE, 0 , nullptr , 0 ); } DistributedLock::~DistributedLock () { zookeeper_close (zk_handle_.get ()); } bool DistributedLock::lock () std::string node_name = zoo_create (zk_handle_.get (), (lock_path_ + "/" ).c_str (), NULL , -1 , &ZOO_OPEN_ACL_UNSAFE, ZOO_EPHEMERAL | ZOO_SEQUENCE, NULL , 0 ); if (node_name.empty ()) { return false ; } std::vector<std::string> children; get_children (lock_path_, children); std::sort (children.begin (), children.end ()); if (node_name == (lock_path_ + "/" + children.front ())) { return true ; } int index = std::distance (children.begin (), std::lower_bound (children.begin (), children.end (), node_name.substr (lock_path_.size ()+1 ))); std::string prev_node_name = lock_path_ + "/" + children[index-1 ]; return wait_for_event (prev_node_name, 50 ); } bool DistributedLock::unlock () return delete_node (node_path_); }
通过 ZooKeeper 实现可重入的分布式锁,可以使用两种方式来实现:
在客户端实现可重入分布式锁,需要在客户端维护一个计数器,记录当前进程持有锁的数量,并且在释放锁时减少计数器。这样可以保证同一进程多次获取同一个锁时,不会因为重复获取而导致死锁。
在服务端实现可重入分布式锁,则需要在节点数据中保存当前持有该锁的客户端ID和计数器。当一个客户端再次请求同一个锁时,服务端判断是否是同一客户端,并且增加该客户端持有该锁的计数器即可。
Redis则提供了一种基于SETNX命令的分布式锁实现,可以通过在Redis中保存一个标志位来表示锁的占有状态。性能好,适合高并发场景,但数据不是强一致,数据可能丢失,以广播的方式进行锁释放通知,引起惊群。
redis挂了怎么办?不要去做HA、主从、主备(同步的是全量数据,不是强一致性),分片集群即使有多个分片,也不一定同步及时,所以也不行。直接用单机redis,要做隔离,最多出现不可用。
伪代码:
1 2 3 4 5 6 7 set lock uuid ex 30 nx if redis.call("get" , "lock" ) == uuid then redis.call("del" , "lock" ) publish channel 1 end
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 try { redissonLock.lock(); int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock" )); if (stock > 0 ) { int realStock = stock - 1 ; stringRedisTemplate.opsForValue().set("stock" , realStock); System.out.println("扣减成功,剩余库存:" + realStock); } else { System.out.println("扣减失败,库存不足" ); } } finally { redissonLock.unlock(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 if (redis.call('exists' , KEYS[1 ]) == 0 ) then redis.call('hset' , KEYS[1 ], ARVG[2 ], 1 ); redis.call('pexpire' , KEYS[1 ], ARVG[1 ]); return nil ; end ;if (redis.call('hexists' , KEYS[1 ], ARGV[2 ]) == 1 ) then redis.call('hincrby' , KEYS[1 ], ARVG[2 ], 1 ); redis.call('pexpire' , KEYS[1 ], ARVG[1 ]); return nil ; end ;redis.call('subscibe' , channel); return redis.call('pttl' , KEYS[1 ]); if (redis.call('hexists' , KEYS[1 ], ARVG[2 ]) == 1 ) then redis.call('pexpire' , KEYS[1 ], ARVG[1 ]); return 1 ; end ;return 0 ;if redis.call('hexists' , KEYS[1 ], ARGV[3 ]) == 0 then return nil ; end ;local counter = redis.call('hincrby' , KEYS[1 ], ARGV[3 ], -1 ); if (counter > 0 ) then redis.call('pexpire' , KEYS[1 ], ARGV[2 ]); return 0 ; else redis.call('del' , KEYS[1 ]); redis.call('publish' , KEYS[2 ], ARGV[1 ]); return 1 ; end ;return nil ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <iostream> #include <string> #include <chrono> #include <thread> #include <hiredis/hiredis.h> class RedisLocker {public : RedisLocker (std::string host, int port) { context = redisConnect (host.c_str (), port); } ~RedisLocker () { redisFree (context); } bool try_lock (std::string key, int timeout = 1000 ) struct timespec ts; clock_gettime (CLOCK_REALTIME, &ts); ts.tv_sec += timeout / 1000 ; timeout %= 1000 ; ts.tv_nsec += timeout * 1000000 ; while (true ) { redisReply* reply = (redisReply*)redisCommand (context, "SETNX %s 1" , key.c_str ()); if (reply != NULL && reply->type == REDIS_REPLY_INTEGER && reply->integer == 1 ) { freeReplyObject (reply); return true ; } else { freeReplyObject (reply); std::this_thread::sleep_for (std::chrono::milliseconds (10 )); } struct timespec now; clock_gettime (CLOCK_REALTIME, &now); if (now.tv_sec > ts.tv_sec || (now.tv_sec == ts.tv_sec && now.tv_nsec >= ts.tv_nsec)) { break ; } } return false ; } void unlock (std::string key) redisReply* reply = (redisReply*)redisCommand (context, "DEL %s" , key.c_str ()); freeReplyObject (reply); } private : redisContext* context; };
使用expire来实现过期,但是setnx和expire分开了,不是原子操作,setnx后进程崩溃了就无法解锁了。
1 2 3 4 5 6 7 8 9 10 11 12 function acquire_lock(lock_name, expiration_time): setnx_result = redis.setnx(lock_name, 1 ) if setnx_result == 1 : redis.expire(lock_name, expiration_time) return True else : return False function release_lock(lock_name): redis.delete(lock_name)
将value值设置为当前时间加上过期时间,并在获取锁时检查是否超时。通过将锁的value值设置为当前时间加上过期时间来实现锁的超时机制。当获取锁失败时,检查锁的当前值是否小于当前时间,如果小于,则说明锁已经超时,此时通过getset命令获取当前值并设置新值,如果设置成功则表示获取锁成功;否则,说明锁已经被其他进程持有,获取锁失败。
过期时间是客户端自己生成的,必须要求分布式环境下,每个客户端的时间必须同步。
如果锁过期的时候,并发多个客户端同时请求过来,都执行getset,最终只能有一个客户端加锁成功,但是该客户端锁的过期时间,可能被别的客户端覆盖。
该锁没有保存持有者的唯一标识,可能被别的客户端释放/解锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 $lock_name = 'my_lock_name' ; $expire_time = 5000 ; $redis = new Redis ();$redis ->connect ('127.0.0.1' , 6379 );$lock_value = time () + $expire_time ;$success = $redis ->setnx ($lock_name , $lock_value );if ($success ) { $redis ->pexpire ($lock_name , $expire_time ); return true ; } else { $current_value = $redis ->get ($lock_name ); if ($current_value && $current_value < time ()) { $old_value = $redis ->getset ($lock_name , $lock_value ); if ($old_value && $old_value == $current_value ) { $redis ->pexpire ($lock_name , $expire_time ); return true ; } } return false ; } $current_value = $redis ->get ($lock_name );if ($current_value && $current_value >= time ()) { $redis ->del ($lock_name ); return true ; } else { return false ; }
Lua脚本来保证原子性(包含setnx和expire两条指令),不推荐用redis事务机制。因为我们的生产环境,基本都是redis集群环境,做了数据分片操作。你一个事务中有涉及到多个key操作的时候,这多个key不一定都存储在同一个redis-server上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 class RedisLock {public : RedisLock (const char * name, const char * address, int port) : m_name (name), m_address (address), m_port (port) {} ~RedisLock () { if (m_redis) { redisFree (m_redis); } } bool lock (int timeout) using namespace std::chrono; m_redis = redisConnect (m_address.c_str (), m_port); if (!m_redis || m_redis->err) { std::cerr << "Failed to connect to Redis server: " << m_redis ? m_redis->errstr : "unknown error" << std::endl; return false ; } milliseconds start = duration_cast <milliseconds>(system_clock::now ().time_since_epoch ()); while (true ) { std::string value = std::to_string (start.count () + timeout * 1000 + 1 ); redisReply* reply = static_cast <redisReply*>(redisCommand (m_redis, "SET %s %s NX EX %d" , m_name.c_str (), value.c_str (), timeout)); if (!reply || reply->type != REDIS_REPLY_STATUS || strcmp (reply->str, "OK" ) != 0 ) { freeReplyObject (reply); std::this_thread::sleep_for (std::chrono::milliseconds (10 )); continue ; } freeReplyObject (reply); return true ; } } void unlock () if (m_redis) { redisReply* reply = static_cast <redisReply*>(redisCommand (m_redis, "DEL %s" , m_name.c_str ())); freeReplyObject (reply); } } private : std::string m_name; std::string m_address; int m_port; redisContext* m_redis = nullptr ; };
首先使用SET命令尝试向Redis服务器设置键值对,并且带有NX和PX选项。如果返回值为“OK”,则表示成功获取到锁,此时可以执行业务逻辑。接着使用GET命令获取当前锁的值,并判断其是否与之前设置的随机值相等,如果相等说明获取到的锁依然是当前客户端持有的,此时可以释放锁;否则说明锁已经被其他客户端获取,在这种情况下,当前客户端不应该主动释放锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def acquire_redis_lock (redis_client, key, value, expire_time ): lua_script = ''' if redis.call("GET", KEYS[1]) == ARGV[1] then redis.call("DEL", KEYS[1]) return true else return false end ''' set_result = redis_client.execute_command('SET' , key, value, 'NX' , 'PX' , expire_time) if set_result == b'OK' : lock_value = redis_client.get(key) if lock_value == value.encode('utf-8' ): redis_client.eval (lua_script, 1 , key, value.encode('utf-8' )) return True else : return False else : return False
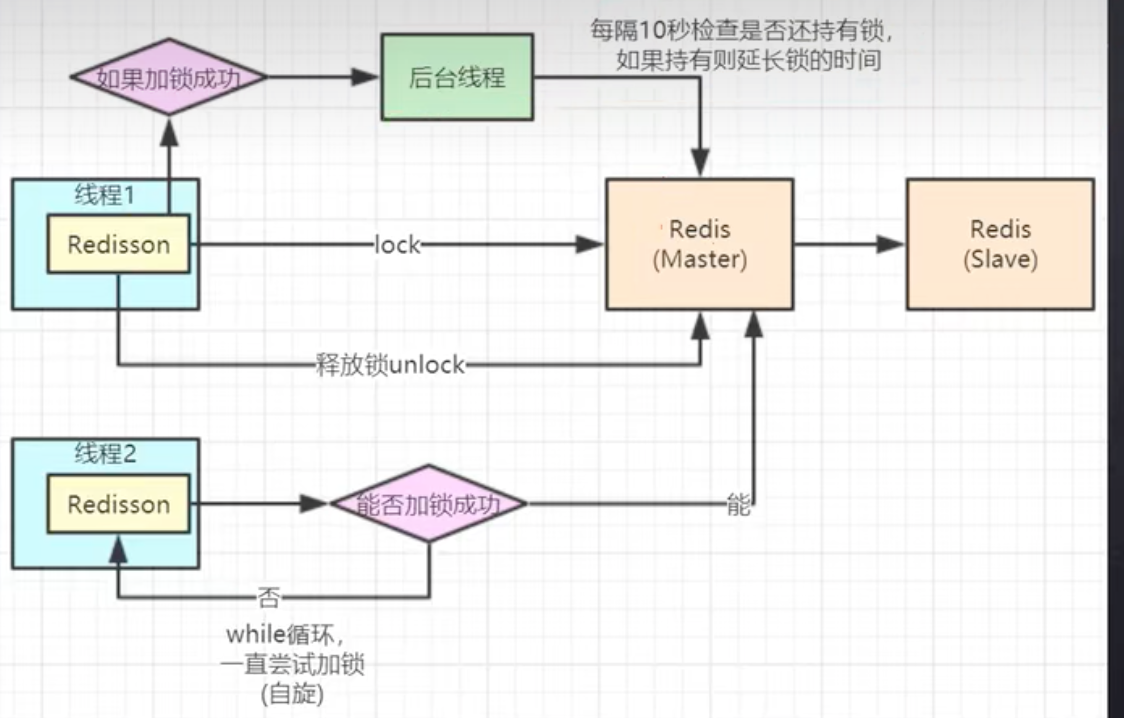
是否可以给获得锁的线程,开启一个定时守护线程,每隔一段时间检查锁是否还存在,存在则对锁的过期时间延长,防止锁过期提前释放。参考java的Redisson。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 redis_lock = RedissonLock(key, ttl) if redis_lock.acquire(): def renew_thread (): while redis_lock.locked: redis_lock.renew() time.sleep(redis_lock.ttl * 0.8 ) t = threading.Thread(target=renew_thread) t.start() redis_lock.release() else : print ("Failed to acquire lock" )
如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
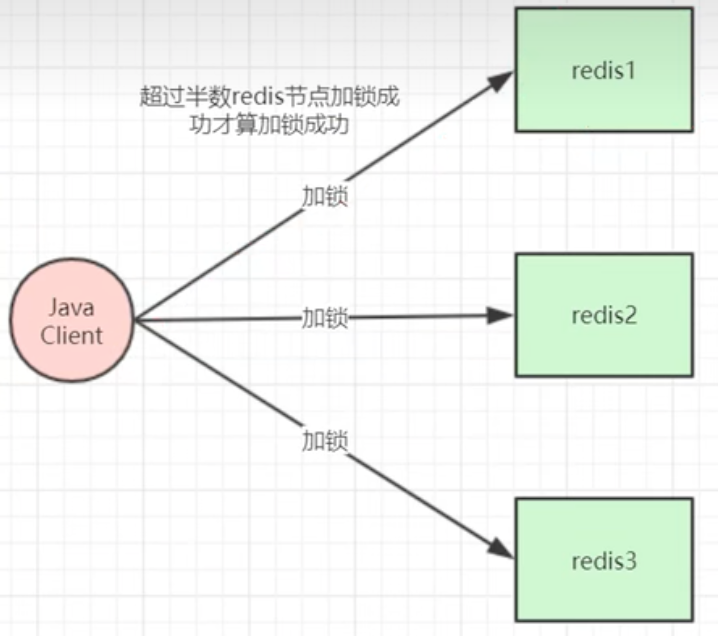
RedLock是一种基于Redis的分布式锁实现方案,其实现步骤如下:
初始化Redis集群:至少需要3个独立的Redis节点组成伪集群,redis之间不需要通信。
获取当前时间戳和唯一标识符:所有客户端获取的时间戳必须相同且精确到毫秒级别,同时每个客户端都要生成一个唯一的标识符,可以是UUID或其他随机数。
计算加锁过期时间并尝试获取锁:通过向Redis集群的每个节点顺序(预防都没有抢到过半的锁,如果由于分区隔离确实抢不到,则重新抢锁)发送SET命令实现加锁,同时指定过期时间为固定值。如果客户端在超时之前成功地从大多数Redis节点上获取了锁,则认为该客户端已经获得了锁,全量抢锁存在可用性问题,只要抢到过半就行。
释放锁:如果需要释放锁,客户端必须向所有Redis节点发送DEL命令,以确保所有节点上的锁都被正确地释放。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import redisimport timeclass RedLock (object ): def __init__ (self, key, connection_details, retry_times=3 , retry_delay=0.2 , clock_drift=0.01 ): self .key = key self .retry_times = retry_times self .retry_delay = retry_delay self .clock_drift = clock_drift self .redis_connections = [] for conn_detail in connection_details: self .redis_connections.append(redis.StrictRedis(host=conn_detail['host' ], port=conn_detail['port' ], db=conn_detail['db' ])) def _lock_instance (self, redis_conn, ttl, uuid ): return redis_conn.set (self .key, uuid, nx=True , px=ttl) def lock (self, ttl=10000 , timeout=1000 ): n = len (self .redis_connections) start_time = time.time() * 1000 uuid = str (uuid.uuid4()) while (time.time() * 1000 - start_time) < timeout: acquired_count = 0 for redis_conn in self .redis_connections: if self ._lock_instance(redis_conn, ttl, uuid): acquired_count += 1 quorum = n // 2 + 1 if acquired_count >= quorum: return uuid for redis_conn in self .redis_connections: if redis_conn.get(self .key) == uuid: redis_conn.delete(self .key) time.sleep(self .retry_delay) raise Exception('Failed to acquire lock' ) def unlock (self, uuid ): for redis_conn in self .redis_connections: if redis_conn.get(self .key) == uuid: redis_conn.delete(self .key)
为了实现可重入锁,我们可以将锁的value由一个随机字符串改为一个计数器,并使用Lua脚本来保证原子性地进行加减操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 if redis.call("exists" , KEYS[1 ]) == 0 then redis.call("hset" , KEYS[1 ], ARGV[2 ], 1 ) redis.call("pexpire" , KEYS[1 ], ARGV[1 ]) return 1 end if redis.call("hexists" , KEYS[1 ], ARGV[2 ]) == 1 then redis.call("hincrby" , KEYS[1 ], ARGV[2 ], 1 ) redis.call("pexpire" , KEYS[1 ], ARGV[1 ]) return 1 end return 0
该脚本接受三个参数:第一个参数是锁的名称,第二个参数是当前线程的标识符,第三个参数是锁的过期时间(单位为毫秒)。
该脚本的作用是,如果缓存中不存在该锁,则创建一个新的锁,并将当前线程的计数器设置为1;如果缓存中存在该锁并且当前线程已经持有该锁,则将当前线程的计数器加1;否则无法获取锁,返回0。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 if redis.call("exists" , KEYS[1 ]) == 0 then return 0 end local counter = redis.call("hget" , KEYS[1 ], ARGV[2 ])if not counter then return 0 elseif tonumber (counter) > 1 then redis.call("hincrby" , KEYS[1 ], ARGV[2 ], -1 ) return 1 else redis.call("del" , KEYS[1 ]) return 1 end
该脚本也接受三个参数,第一个参数是锁的名称,第二个参数是当前线程的标识符。该脚本的作用是,如果当前线程未持有该锁,则直接返回0;如果当前线程持有该锁但是计数器大于1,则将计数器减1;否则,将该锁删除。
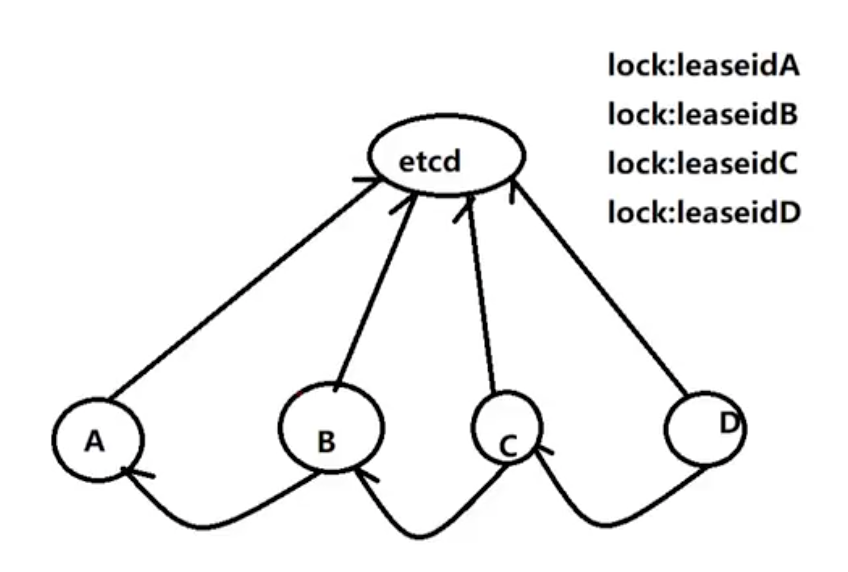
使用etcd实现分布式锁通常需要以下步骤:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import ( "go.etcd.io/etcd/clientv3" "go.etcd.io/etcd/clientv3/concurrency" ) func main () cli, err := clientv3.New(clientv3.Config{ Endpoints: []string {"localhost:2379" }, DialTimeout: 5 * time.Second, }) if err != nil { panic (err) } defer cli.Close() session, err := concurrency.NewSession(cli) if err != nil { panic (err) } mutex := concurrency.NewMutex(session, "/my-lock" ) if err := mutex.Lock(context.Background()); err != nil { panic (err) } defer mutex.Unlock(context.Background()) }
实现高可用性和容错性 当出现网络异常或者宕机等故障时,需要保证分布式锁服务的高可用性和容错性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 class DistributedLock {public : DistributedLock (const std::vector<std::string>& zk_hosts, const std::string& lock_path, const std::string& node_path); ~DistributedLock (); bool lock () bool unlock () private : std::vector<std::shared_ptr<zookeeper_handle_t >> zk_handles_; std::string lock_path_; std::string node_path_; }; DistributedLock::DistributedLock (const std::vector<std::string>& zk_hosts, const std::string& lock_path, const std::string& node_path) : lock_path_ (lock_path), node_path_ (node_path) { for (const auto & host : zk_hosts) { std::shared_ptr<zookeeper_handle_t > zk_handle = std::make_shared <zookeeper_handle_t >(); zookeeper_init (zk_handle.get (), host.c_str (), 5000 , NULL , NULL , 0 ); zk_handles_.push_back (zk_handle); } } DistributedLock::~DistributedLock () { for (const auto & zk_handle : zk_handles_) { zookeeper_close (zk_handle.get ()); } } bool DistributedLock::lock () std::vectorstd::string node_names; for (const auto & zk_handle : zk_handles_) { std::string node_name = zoo_create (zk_handle.get (), (lock_path_ + "/" ).c_str (), NULL , -1 , &ZOO_OPEN_ACL_UNSAFE, ZOO_EPHEMERAL | ZOO_SEQUENCE, NULL , 0 ); if (node_name.empty ()) { return false ; } node_names.push_back (node_name); } std::vector<std::string> children; for (const auto & zk_handle : zk_handles_) { get_children (zk_handle.get (), lock_path_, children); } std::sort (children.begin (), children.end ()); std::string min_node_name = lock_path_ + "/" + children.front (); for (const auto & node_name : node_names) { if (node_name == min_node_name) { continue ; } delete_node (node_name); } return true ; } bool DistributedLock::unlock () return delete_node (node_path_); }
在代码示例中,涉及到了一些函数的调用,下面给出这些函数的实现参考:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 void get_children (zookeeper_handle_t * zk_handle, const std::string& path, std::vector<std::string>& children) struct String_vector str_vec; int ret = zoo_get_children (zk_handle, path.c_str (), 0 , &str_vec); if (ret == ZOK) { for (int i = 0 ; i < str_vec.count; ++i) { children.push_back (str_vec.data[i]); } deallocate_String_vector (&str_vec); } } bool delete_node (const std::string& node_path) int ret = zoo_delete (zk_handle_.get (), node_path.c_str (), -1 ); return (ret == ZOK); } void lock_watcher (zhandle_t *zh, int type, int state, const char *path, void *watcher_ctx) if (type == ZOO_DELETED_EVENT && path != nullptr && node_path.compare (path) == 0 ) { cout << "Lock node has been deleted!" << endl; cv.notify_all (); } } bool wait_for_event (const std::string& node_name, int timeout_ms) zoo_exists (zk_handle_.get (), node_name.c_str (), lock_watcher, nullptr , nullptr ); unique_lock<mutex> lk (m) ; if (cv.wait_for (lk, timeout_ms + get_timestamp_ms ()) == cv_status::timeout) { return false ; } else { return true ; } } int64_t get_timestamp_ms () struct timeval tv; gettimeofday (&tv, NULL ); return (int64_t )tv.tv_sec * 1000 + tv.tv_usec / 1000 ; }
分布式锁不仅可以使用 ZooKeeper 实现,还可以使用 Redis、etcd 等其他分布式协调服务来实现。
并发控制
数据同步问题:如何确保不同节点上的数据副本保持同步?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct Node { uint32_t version; }; void sync (Node& a, Node& b) if (a.version == b.version) { return ; } if (a.version > b.version) { merge (b, a); } else { merge (a, b); } }
在分布式系统中,保证多个操作的原子性是非常重要的。因此需要实现分布式事务,以保证多个操作在所有节点上都成功或者都失败。常用的分布式事务实现包括Two-Phase Commit(2PC)和Saga等。其中,2PC是一种经典的分布式事务实现,它通过协调器协调各个节点的事务提交过程,以确保所有节点的事务要么全部提交要么全部回滚。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 #include <iostream> #include <string> #include <vector> #include <unordered_map> #include <chrono> #include <thread> #include <hiredis/hiredis.h> class TwoPhaseCommit {public : TwoPhaseCommit (std::string host, int port) { context = redisConnect (host.c_str (), port); } ~TwoPhaseCommit () { redisFree (context); } bool prepare (std::string key, std::string value) std::vector<std::string> participants = getParticipants (key); std::unordered_map<std::string, bool > votes; for (auto participant : participants) { redisReply* reply = (redisReply*)redisCommand (context, "MULTI\nSET %s %s\nEXEC" , key.c_str (), value.c_str ()); if (reply == NULL || reply->type != REDIS_REPLY_ARRAY || reply->elements != 2 ) { freeReplyObject (reply); return false ; } bool success = (reply->element[1 ]->type == REDIS_REPLY_STATUS && strcmp (reply->element[1 ]->str, "OK" ) == 0 ); freeReplyObject (reply); votes[participant] = success; } bool commit = true ; for (auto vote : votes) { if (!vote.second) { commit = false ; break ; } } std::string cmd = commit ? "EXEC" : "DISCARD" ; bool ret = true ; for (auto participant : participants) { redisReply* reply = (redisReply*)redisCommand (context, "MULTI\n%s\nDEL __%s\nEXEC" , cmd.c_str (), participant.c_str ()); if (reply == NULL || reply->type != REDIS_REPLY_ARRAY || reply->elements != 2 ) { freeReplyObject (reply); ret = false ; continue ; } if (commit) { ret = (reply->element[0 ]->type == REDIS_REPLY_STATUS && strcmp (reply->element[0 ]->str, "OK" ) == 0 ); } freeReplyObject (reply); } return ret; } private : redisContext* context; std::vector<std::string> getParticipants (std::string key) { std::vector<std::string> participants; participants.push_back ("node1" ); participants.push_back ("node2" ); participants.push_back ("node3" ); return participants; } };
冲突检测和解决问题:如何检测到不同节点对同一数据对象的操作冲突,并解决这些冲突?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class MVCC {public : MVCC () : current_ts (0 ) {} void start_transaction () current_ts++; } bool read (int key, std::string& value, long long & ts) auto iter = data.find (key); if (iter == data.end ()) { return false ; } if (iter->second.ts > current_ts) { return false ; } value = iter->second.value.back (); ts = iter->second.ts; return true ; } void write (int key, const std::string& value) auto & entry = data[key]; entry.value.push_back (value); entry.ts = current_ts; } private : struct Entry { std::vector<std::string> value; long long ts; }; std::unordered_map<int , Entry> data; long long current_ts; };
利用分布式锁来避免数据更新冲突:分布式锁可以用来保证只有一个节点能够修改数据,从而避免数据更新冲突问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class DistributedLock {public : DistributedLock (const std::string& zk_servers, const std::string& lock_path) { zk_handle = zookeeper_init (zk_servers.c_str (), NULL , 30000 , NULL , NULL , 0 ); path = lock_path; } ~DistributedLock () { zookeeper_close (zk_handle); } bool acquire_lock () char buf[1024 ]; int buflen = sizeof (buf); int ret = zoo_create (zk_handle, path.c_str (), "" , 0 , &ZOO_OPEN_ACL_UNSAFE, 0 , buf, buflen); if (ret == ZOK) { return true ; } else if (ret == ZNODEEXISTS) { return false ; } else { return false ; } } bool release_lock () int ret = zoo_delete (zk_handle, path.c_str (), -1 ); if (ret == ZOK) { return true ; } else { return false ; } } private : zhandle_t * zk_handle; std::string path; };
分布式计算或存储 分布式计算或存储是指将计算任务和数据存储在多台计算机上,通过网络互联实现协同工作。它可以提高计算效率,减少单点故障的风险,并支持大规模数据处理和分析。作为一种重要的分布式系统应用,它已经广泛应用于云计算、物联网、大数据分析等领域。
Spark 和 Hadoop 是两个不同的分布式计算框架,虽然它们都可以用于大规模数据处理和分析,但是在某些方面有一些区别。
计算模型
内存管理
支持的语言
生态系统
我们应该将 Spark 看作是 Hadoop MapReduce 的一个替代品而不是 Hadoop 的替代品。其意图并非是替代 Hadoop,而是为了提供一个管理不同的大数据用例和需求的全面且统一的解决方案。
总体来说,Spark 和 Hadoop 都是非常优秀的分布式计算框架,具有各自的优势和特点。在选择使用哪个框架时,需要根据具体的业务需求和数据处理场景进行评估和选择。
解决什么问题 分布式计算或存储的目标是解决如何快速、可靠地处理大量数据的问题。在传统的计算模型中,单个计算机的处理能力有限,而且容易出现瓶颈。当需要处理海量数据时,单个计算机已经无法胜任。因此,采用分布式计算或存储可以有效解决这些问题。
数据一致性 在分布式存储系统中,多个节点同时访问同一份数据时,需要保证数据的一致性。然而,由于网络延迟、故障恢复等因素的影响,数据的一致性很容易受到破坏。
数据一致性问题的解决方法有很多,比如基于副本的数据复制、基于版本号的数据协调、基于锁的并发控制等,但每种方法都有其局限性和挑战性。例如,基于副本的数据复制可能会导致数据过期和冲突,而基于版本号的数据协调可能会造成大量的消息通信和资源消耗。
基于Paxos算法的一致性协议
基于Raft算法的一致性协议
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 struct PaxosMessage { int proposal_id; int value; }; enum PaxosRole { PROPOSER, ACCEPTOR, LEARNER };class PaxosAlgorithm {public : void prepare (int proposal_id) for (int i = 0 ; i < acceptors.size (); ++i) { send_prepare_request (acceptors[i], proposal_id); } for (int i = 0 ; i < acceptors.size (); ++i) { PaxosMessage msg = receive_acceptor_response (); if (msg.proposal_id > max_proposal_id) { max_proposal_id = msg.proposal_id; max_accepted_value = msg.value; } } } void accept (int proposal_id, int value) for (int i = 0 ; i < acceptors.size (); ++i) { send_accept_request (acceptors[i], proposal_id, value); } } void learn () for (int i = 0 ; i < learners.size (); ++i) { send_learn_request (learners[i],max_proposal_id, max_accepted_value); } } private : vector<PaxosRole> roles; vector<int > acceptors; vector<int > learners; int max_proposal_id; int max_accepted_value; void send_prepare_request (int acceptor, int proposal_id) } void send_accept_request (int acceptor, int proposal_id, int value) } void send_learn_request (int learner, int proposal_id, int value) } PaxosMessage receive_acceptor_response () { } }; int main () PaxosAlgorithm paxos; paxos.prepare (1 ); paxos.accept (1 , 10 ); paxos.learn (); return 0 ; }
对于基于Raft算法的实现,与Paxos算法相比,其核心逻辑和实现方式有所不同。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 struct RaftMessage { int term; int leader_id; int prev_log_index; int prev_log_term; vector<LogEntry> entries; int leader_commit; }; enum RaftRole { FOLLOWER, CANDIDATE, LEADER };class RaftAlgorithm {public : void request_vote (int term, int candidate_id, int last_log_index, int last_log_term) for (int i = 0 ; i < peers.size (); ++i) { send_request_vote (peers[i], term, candidate_id, last_log_index, last_log_term); } int votes = 0 ; for (int i = 0 ; i < peers.size (); ++i) { bool vote_granted = receive_vote_response (); if (vote_granted) { votes++; } } if (votes > peers.size () / 2 ) { become_leader (); } else { become_candidate (); } } void append_entries (int leader_term, int leader_id, int prev_log_index, int prev_log_term, vector<LogEntry> entries, int leader_commit) if (entries.empty ()) { return ; } if (!check_log_match (prev_log_index, prev_log_term)) { return ; } add_new_entries (entries); commit_new_entries (leader_commit); become_follower (); } private : vector<RaftRole> roles; vector<int > peers; int current_term; int voted_for; int commit_index; int last_applied; void send_request_vote (int peer, int term, int candidate_id, int last_log_index, int last_log_term) } bool receive_vote_response () } bool check_log_match (int prev_log_index, int prev_log_term) } void add_new_entries (vector<LogEntry> entries) } void commit_new_entries (int leader_commit) } void become_follower () } void become_candidate () } void become_leader () } }; int main () RaftAlgorithm raft; raft.request_vote (1 , 2 , 3 , 4 ); raft.append_entries (5 , 6 , 7 , 8 , {}, 9 ); return 0 ; }
容错性 由于分布式计算或存储涉及到多个节点,其中任何一个节点出现故障都可能影响整个系统的可用性。因此,如何设计容错机制,保障整个系统的稳定性是非常重要的。
可以使用备份技术来实现容错性,将数据存储到多个节点上,在其中一些节点出现故障时,可以从备份节点上恢复数据。
1 2 3 4 5 6 7 8 9 10 void Put (const std::string& key, const std::string& value) std::vector<NodeID> nodes = hash_ring_.GetNodes (key); for (auto & node : nodes) { auto iter = stores_.find (node); if (iter != stores_.end ()) { iter->second.Put (key, value); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import socketimport timeclass HeartbeatMonitor (object ): def __init__ (self, nodes=[] ): self .nodes = nodes def monitor (self ): while True : for node in self .nodes: if not self .check_alive(node): self .handle_failure(node) time.sleep(5 ) def check_alive (self, node ): try : sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.settimeout(1 ) sock.connect((node, 8080 )) sock.close() return True except : return False def handle_failure (self, node ): print ("Node %s has failed" % node) nodes = ['192.168.1.1' , '192.168.1.2' , '192.168.1.3' ] monitor = HeartbeatMonitor(nodes=nodes) monitor.monitor()
数据分片和负载均衡 通常采用哈希算法对数据进行分片,并采用负载均衡算法将这些数据分配到不同的计算节点上。例如,使用一致性哈希算法将数据映射到一个虚拟环上,然后根据节点的数量、负载情况等动态调整虚拟节点与物理节点的对应关系,以实现负载均衡。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import hashlibclass ConsistentHashing (object ): def __init__ (self, nodes=[], replicas=3 ): self .replicas = replicas self .hash_ring = {} for node in nodes: self .add_node(node) def add_node (self, node ): for i in range (self .replicas): key = self .gen_key('%s:%d' % (node, i)) self .hash_ring[key] = node def remove_node (self, node ): for i in range (self .replicas): key = self .gen_key('%s:%d' % (node, i)) del self .hash_ring[key] def get_node (self, key ): if not self .hash_ring: return None hash_key = self .gen_key(key) for node_key in sorted (self .hash_ring.keys()): if hash_key <= node_key: return self .hash_ring[node_key] def gen_key (self, key ): m = hashlib.md5() m.update(key.encode('utf-8' )) return int (m.hexdigest(), 16 ) nodes = ['192.168.1.1' , '192.168.1.2' , '192.168.1.3' ] c_hash = ConsistentHashing(nodes=nodes, replicas=3 ) print (c_hash.get_node('foo' ))