protobuf通信协议
包完整性
- 以特殊符号来分界,如每个包都以特定的字符来结尾(如\r\n,http的header就是),当在字节流中读取到该字符时,则表明上一个包到此为止。
- 固定包头+包体结构,包头一般时一个固定字节长度的结构,并且包头中会有一个特定的字段指定包体的大小。收包时,先接收固定字节数的头部,解出这个包的完整长度,按此长度接收包体。header+body 目前应用最多的一种包格式。
- 在序列化后的buffer前面增加一个字符流的头部,其中有一个字段存储包总长度,根据特殊字符(比如\n或者\0)判断头部的完整性。这样通常比2麻烦些,http和redis($6\r\nfoobar\r\n)采用的这种形式,收包的时候,先判断已经收到的数据中是否包含结束符,收到结束符后解析包头,解出这个包完整长度,按此长度接收包体。
协议设计
序列号:tcp只能保证数据到达,不能保证数据是否处理。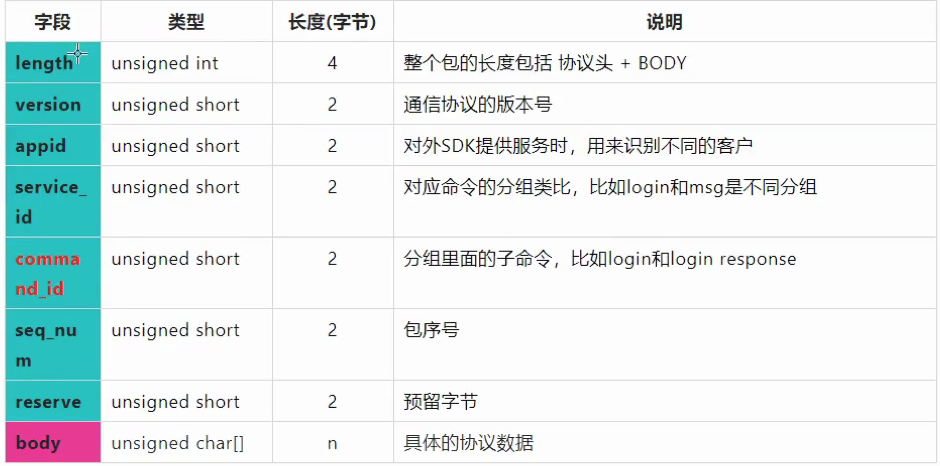
type表示协议类型,如xml,json。
版本号尽量放在前面,读取版本号的时候可以少读一些字节,如下nginx。protobuf封装后是放在body里面的。header也是定长的,就不用序列化。body做序列化即可。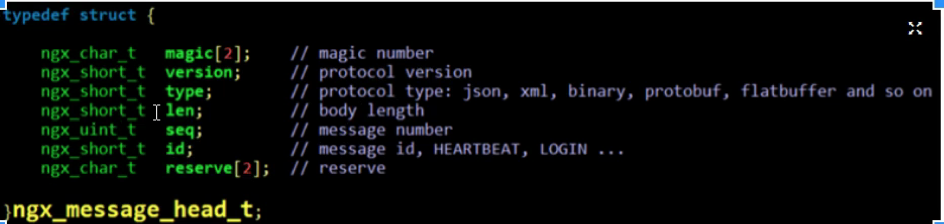
http请求头为文本,但是body如果传的是jpeg就是二进制。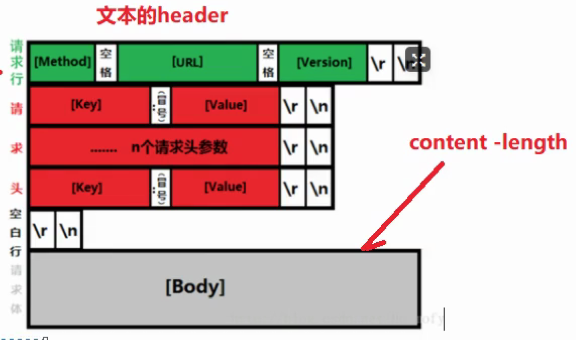
xml、json序列化后都是文本,protobuf序列化后就是二进制,这里指的是将对象序列化,对象里面一些变长的字段不进行序列化不方便传输。
编码原理
varints编码
通常来说,普通的int数据类型,无论其值大小,所占有的存储空间都是相等的,这点引起了人们的思考,是否可以根据数值的大小来动态地占有存储空间,使得比较小的数字占有较小的字节数,值相对比较大的数字占用较多的字节数,这便是变长整形编码的基本思想。
1 | field_num + wire type + (len) + value |
value采用base128,小端模式,低位字节在前面(底层好处理些,整数先处理地位,低位处理完左移就行),最高位bit表示后面还有没有更高字节的数据,剩下7个bit表示数据位,如果2个字节表示:1xxx xxxx 0xxx xxxx;3个字节表示:1xxx xxxx 1xxx xxxx 0xxx xxxx。
666整数的16进制为0x29A,即0000 0010 1001 1010,这是大端模式,根据7bit数据位隔开0000101 0011010,再转为小端模式,0011010 0000101,再加上标志位:10011010 00000101,即9A 05。
protobuf内部将int32类型的负数转换为uint64来处理,7*9+1=64,需要10个字节。比如整数-5,先取5的原码:00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000101,得反码:11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111010,对反码加1得补码:11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111011,这是-5在计算机里面的二进制表示。转成每7bit占有1个字节:1 1111111 1111111 1111111 1111111 1111111 1111111 1111111 1111111 1111011,然后高地址存储到低地址,并且不是结束字节需要最高位置1,即是:11111011 11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111 00000001,转成16进制:fb ff ff ff ff ff ff ff ff 01,数据本身就占用了10字节。