什么叫ARTS? 每周完成一个ARTS:
Algorithm:每周至少做一个 leetcode 的算法题
Review:阅读并点评至少一篇英文技术文章
Tip:学习至少一个技术技巧
Share:分享一篇有观点和思考的技术文章
作者:陈皓https://www.zhihu.com/question/301150832/answer/529809529
Reverse String 翻转字符串char[],O(1)空间复杂度。
1 2 Input: ["h" ,"e" ,"l" ,"l" ,"o" ] Output: ["o" ,"l" ,"l" ,"e" ,"h" ]
方法一
从数组的头尾同时遍历,交换方法为a=a^b;b=a^b;a=a^b;
如果中间还剩一个,就不处理。
1 2 3 4 5 6 7 8 9 10 11 12 class Solution {public : void reverseString (vector<char >& s) if (s.size ()<=1 ) return ; for (int i=0 ,j=s.size ()-1 ;i<j;i++,j--) { s[i]=s[i]^s[j]; s[j]=s[i]^s[j]; s[i]=s[i]^s[j]; } } };
方法二
直接调用算法
1 2 3 4 5 6 class Solution {public : void reverseString (vector<char >& s) reverse (s.begin (), s.end ()); } };
Reverse Integer 32位有符号整形,将数字部分颠倒,如果颠倒后异常,需要处理为0。
1 2 Input: -123 Output: -321
方法一
需要依次取出各位至数组中。
然后采用算法颠倒。
再依次打包成整数,如果溢出,再进行处理。如果a*b>max,则有a>max/b。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public : bool isOverFlow (int a, int b) if (a>0 && b>0 ) return (INT_MAX-a)/10 <b; else if (a<0 && b<0 ) return (INT_MIN-a)/10 >b; else return false ; } int reverse (int x) vector<int > temp; int y=0 ; while (x/10 ) { temp.push_back (x%10 ); x/=10 ; } temp.push_back (x%10 ); for (int i=0 ;i<temp.size ();i++) { if (isOverFlow (temp[i], y)) return 0 ; y=y*10 +temp[i]; } return y; } };
方法二
依次取个位的数,同时将这个数放在最高位组合出倒数,一次循环完成。
在循环的过程中,不断检测是否会溢出,如果即将溢出,则直接返回0.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public : bool isOverflow (int a, int b) if (a>0 && b>0 ) { return a>(INT_MAX-b)/10 ; } else if (a<0 && b<0 ) { return a<(INT_MIN-b)/10 ; } else { return false ; } } int reverse (int x) int res=0 ; while (x) { int tmp=x%10 ; if (isOverflow (res, tmp)) return 0 ; res=res*10 +tmp; x/=10 ; } return res; } };
First Unique Character in a String 给一个字符串,找到第一个不是重复的字母,给出地址,在字符串只考虑小写字母的前提下。
1 2 3 4 5 s = "leetcode" return 0. s = "loveleetcode" , return 2.
方法一
从前往后依次将字母存入int数组[26],index为字母,value为个数,由于个数可能有很多,得用int数组才行。
将字符串套入数组检查,找到只出现一次的第一个字母,即value==1,此时的i为地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public : int firstUniqChar (string s) array<int , 26> freq; freq.fill (0 ); for (int i=0 ;i<s.length ();i++) { freq[s[i]-'a' ]++; } for (int i=0 ;i<s.length ();i++) { if (freq[s[i]-'a' ]==1 ) return i; } return -1 ; } };
方法二
从前往后依次存入unordered_map,key为字母,value为个数。
将字符串套入map中检查,找到只出现一次的第一个字母,map的value==1,此时的i为地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution {public : int firstUniqChar (string s) unordered_map<char , int > freq; for (int i=0 ;i<s.length ();i++) { freq[s[i]]++; } for (int i=0 ;i<s.length ();i++) { if (freq[s[i]]==1 ) return i; } return -1 ; } };
方法三 优化点思考,第二轮查找第一个单数的时候不需要重新遍历字符串了,直接遍历更新的字典找到第一个单数。
遍历字符串,更新字典,包括是哪个字符、字符的位置、字符出现的次数。需要用到pair<int, int>
遍历字典,找到字符出现次数等于1且字符的位置最小的那个位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution {public : int firstUniqChar (string s) unordered_map<char ,pair<int ,int >> dic; int index=s.length (); for (int i=0 ;i<s.length ();i++) { dic[s[i]].first=i; dic[s[i]].second++; } for (auto & x: dic) { if (x.second.second==1 ) index=index<x.second.first?index:x.second.first; } if (index==s.length ()) return -1 ; return index; } };
Valid Anagram 判断s是否为t的同字母异序词
1 2 Input: s = "anagram" , t = "nagaram" Output: true
方法一
依次遍历字符串s,建立int[26]数组,存入的是该遍历到的字符个数。
再依次遍历字符串t,检索之前建立的数组,判断遍历到的该字符是否个数为0,否则不是同字母异序词,如果大于0,直接做减减处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public : bool isAnagram (string s, string t) if (s.length ()!=t.length ()) return false ; array<int , 26> freq; freq.fill (0 ); for (int i=0 ;i<s.length ();i++) { freq[s[i]-'a' ]++; } for (int j=0 ;j<t.length ();j++) { if (freq[t[j]-'a' ]) freq[t[j]-'a' ]--; else return false ; } return true ; } };
方法二
依次遍历字符串s,建立字典,存入的是该遍历到的字符个数。
再依次遍历字符串t,检索之前建立的字典,判断遍历到的该字符是否个数为0,否则不是同字母异序词,如果大于0,直接做减减处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution {public : bool isAnagram (string s, string t) if (s.length ()!=t.length ()) return false ; unordered_map<int ,int > freq; for (int i=0 ;i<s.length ();i++) { freq[s[i]]++; } for (int j=0 ;j<t.length ();j++) { if (freq[t[j]]) freq[t[j]]--; else return false ; } return true ; } };
Valid Palindrome 判断字符串是否为回文,假设字符串仅考虑由字母数字组成,忽略大小写,假设空字符为回文。
1 2 Input: "A man, a plan, a canal: Panama" Output: true
方法一
双指针方案,从头和从尾依次遍历并对比,出现不同则退出。
怎么去掉空格,判断大小写,去掉其他符号,注意全都是其他字符串的情况或直接用isalnum函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution {public : char getValue (char & c) if (c>=48 && c<=57 ) return c; else if (c>=65 && c<=90 ) { return c; } else if (c>=97 && c<=122 ) { return c-32 ; } else return 0 ; } bool isPalindrome (string s) int len=s.length (); if (len==0 ) return true ; for (int i=0 ,j=len-1 ;i<j;i++,j--) { char a=getValue (s[i]); while (a==0 &&i<j) { a=getValue (s[++i]); } char b=getValue (s[j]); while (b==0 &&i<j) { b=getValue (s[--j]); } if (a!=b) { return false ; } } return true ; } };
方法二
同样是双指针方法,只是写法不同,先找到alnum字符,采用while if结构,如果不是alnum字符,则进入循环,再查找,只有同时满足时,才进行对比。
进行对比,不同则退出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {public : bool isPalindrome (string s) int len=s.length (); if (len==0 ) return true ; int i=0 , j=len-1 ; while (i<j) { if (!isalnum (s[i])) { i++; } else if (!isalnum (s[j])) { j--; } else { if (tolower (s[i])!=tolower (s[j])) return false ; i++; j--; } } return true ; } };
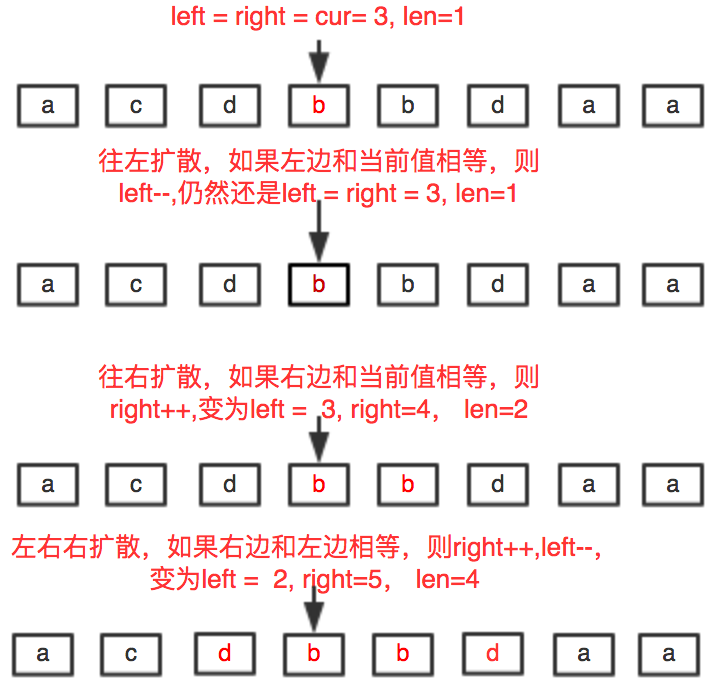
最长回文 给你一个字符串 s,找到 s 中最长的回文子串。
最容易想到的一种方法应该就是 中心扩散法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 string longestPalindrome (string s) { if (s.empty ()) { return "" ; } int strLen = s.size (); int left = 0 ; int right = 0 ; int len = 1 ; int maxStart = 0 ; int maxLen = 0 ; for (int i = 0 ; i < strLen; i++) { left = i - 1 ; right = i + 1 ; while (left >= 0 && s[left] == s[i]) { len++; left--; } while (right < strLen && s[right] == s[i]) { len++; right++; } while (left >= 0 && right < strLen && s[right] == s[left]) { len = len + 2 ; left--; right++; } if (len > maxLen) { maxLen = len; maxStart = left; } len = 1 ; } return s.substr (maxStart + 1 , maxLen); }
回文子串 给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。
首先这一题可以使用动态规划来进行解决:
状态:dp[i][j] 表示字符串s在[i,j]区间的子串是否是一个回文串。
状态转移方程:当 s[i] == s[j] && (j - i < 2 || dp[i + 1][j - 1]) 时,dp[i][j]=true,否则为false
这个状态转移方程是什么意思呢?
当只有一个字符时,比如 a 自然是一个回文串。
当有两个字符时,如果是相等的,比如 aa,也是一个回文串。
当有三个及以上字符时,比如 ababa 这个字符记作串 1,把两边的 a 去掉,也就是 bab 记作串 2,可以看出只要串2是一个回文串,那么左右各多了一个 a 的串 1 必定也是回文串。所以当 s[i]==s[j] 时,自然要看 dp[i+1][j-1] 是不是一个回文串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int countSubstrings (string s) vector<vector<int >> dp (s.size (), vector <int >(s.size (), 0 )); int ans = 0 ; for (int j = 0 ; j < s.size (); j++) { for (int i = 0 ; i <= j; i++) { if (s[i] == s[j] && (j - i < 2 || dp[i + 1 ][j - 1 ])) { dp[i][j] = true ; ans++; } } } return ans; }
String to Integer (atoi) 将字符串转换为数字,如果首部有空格则忽略,其他非数字字符,则返回0,末尾含有字母则忽略,需要考虑负数,数字范围为[−231, 231 − 1]。
1 2 3 4 5 6 7 8 9 10 11 12 Input: " -42" Output: -42 Input: "4193 with words" Output: 4193 Input: "words and 987" Output: 0 Input: "-91283472332" Output: -2147483648
方法一
从头遍历字符串,如果发现有空格则跳过,如果发现时正负符号,则赋给符号变量。
再接着遍历,只对数字进行处理,同时计算数值大小(提前计算是否溢出,如果溢出了,边界值应该怎么给),如果发现有非数字字符,则退出遍历,返回计算结果。
难点:判断是非溢出,及其处理措施?如果a>=0,b>=0,则a*10+b>INT_MAX转化为a>(INT_MAX-b)/10;如果a<0,b<=0(一定要包括0),则a*10+b<INT_MIN转化为a<(INT_MAIN-b)/10;对于没有溢出的情况计算结果为a=a*10+b.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class Solution {public : bool overFlowValue (int & a, int b) if (a>=0 && b>=0 && a>(INT_MAX-b)/10 ) { a = INT_MAX; return true ; } else if (a<0 && b<=0 && a<(INT_MIN-b)/10 ) { a = INT_MIN; return true ; } else { a = a*10 +b; return false ; } } int myAtoi (string str) int flag=1 , value=0 , got=0 ; for (int i=0 ;i<str.length ();i++) { if (got && (str[i]==43 || str[i]==45 || str[i]==32 )) break ; if (!got && str[i]==32 ) continue ; if (!got && str[i]==43 ) { got=1 ; continue ; } else if (!got && str[i]==45 ) { got=1 ; flag=-1 ; continue ; } if (flag==-1 && value>0 ) value*=-1 ; if (str[i]>=48 && str[i]<=57 ) { got=1 ; if (overFlowValue (value, (str[i]-48 )*flag)) { break ; } } else { break ; } } return value; } };
方法二
对前缀进行完善,空格分while循环进行判断,正负号只判断一次,最后再进行数字判断。
对溢出部分进行完善,如何判断a*10+b>INT_MAX?
a*10>INT_MAX
a*10==INT_MAX && b>INT_MAX%10
针对以上两种情况,如果符号位为正,则返回INT_MAX,如果符号位为负,则返回INT_MIN。比如[-10,9],当取直为10时,10>9,如果是负数,返回-10,如果是正数,返回9.
其他情况,返回a*10+b
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public : int myAtoi (string str) int flag=1 , value=0 ; int i=0 ; while (str[i]==' ' ) i++; if (str[i]=='-' ) { flag=-1 ; i++; } else if (str[i]=='+' ) { i++; } for (;i<str.length ();i++) { if (str[i]>='0' && str[i]<='9' ) { if (value>INT_MAX/10 ||(value==INT_MAX/10 && str[i]-'0' >(INT_MAX%10 ))) { if (flag==1 ) return INT_MAX; else return INT_MIN; } value=value*10 +(str[i]-'0' ); } else { break ; } } return value*flag; } };
Implement strStr() 找到当前字符串在另外一个字符串中出现的位置,空字符串按照0处理,找不到返回-1。
1 2 3 4 5 6 Input: haystack = "hello" , needle = "ll" Output: 2 Input: haystack = "aaaaa" , needle = "bba" Output: -1
方法一
两个字符串都从0开始遍历,同时进行比较,如果比较有相同字符,则needle指针加加,如果没有相同字符,则needle置0,haystack指针回退到刚开始对比的下一个位置(重要)。
如果任意一个遍历完,则退出,如果是needle遍历完,还要返回haystack的指针位置-needle长度的位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public : int strStr (string haystack, string needle) if (needle.length ()==0 ) return 0 ; for (int i=0 ,j=0 ;i<haystack.length ();) { if (haystack[i]==needle[j]) { j++; i++; if (j==needle.length ()) return i-j; } else { i=i-j+1 ; j=0 ; } } return -1 ; } };
方法二
使用两个while循环结构,这样就不需要特意进行回退了,但是时间复杂度变大了。
两个字符串都从0开始遍历,均在内循环进行,同时进行比较,如果有相同的字符,则内循环加加,否则退出内循环。
如果外循环遍历完,则退出,如果内循环遍历完,则当前的外循环位置即为需要的地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public : int strStr (string haystack, string needle) if (needle.length ()==0 ) return 0 ; for (int i=0 ;i<haystack.length ();i++) { for (int j=0 ;j<needle.length ();j++) { if (haystack[i+j]!=needle[j]) break ; if (j==needle.length ()-1 ) return i; } } return -1 ; } };
Count and Say count-and-say序列是整数序列,前五个术语如下:
1 2 3 4 5 6 1. 1 2. 11 3. 21 4. 1211 5. 111221
第二个数:一个1,第三个数,两个1,第四个数,一个2,一个1,第五个数,一个1,一个2,两个1.
给出5,要求返回111221.
方法一
从原始字符串前面开始遍历,个数++,遇到不同的数或者原始字符串末尾,则将上一个字符出现的次数以及是哪个字符添加的新字符串末尾。
如果只是不同的数,清空个数。
如果遇到末尾,则将新字符串赋值给原字符串,并清空新字符串/个数,最后退出遍历。
依次递归到第n个,返回此时的字符串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution {public : string countAndSay (int n) { string oldRes="1" ; string newRes="" ; if (n==1 ) return oldRes; int num=0 ; for (int x=1 ;x<n;x++) { for (int i=0 ;i<oldRes.length ();i++) { num++; if (i<oldRes.length ()-1 && oldRes[i]!=oldRes[i+1 ]) { newRes.append (to_string (num)); newRes.push_back (oldRes[i]); num=0 ; continue ; } if (i==oldRes.length ()-1 ) { newRes.append (to_string (num)); newRes.push_back (oldRes[i]); num=0 ; oldRes=newRes; newRes.clear (); break ; } } } return oldRes; } };
方法二
优化点:for循环可以转化为while循环
将赋值的部分提取出来,关键在于怎么找到变化的临界点或者字符串的末尾,只要任意一个不满足就表明是边界了,故用&&语句比较合适。
使用+语句,减少语句。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public : string countAndSay (int n) { if (n==0 ) return "" ; if (n==1 ) return "1" ; string oldStr="1" ; string newStr; while (--n) { newStr="" ; for (int i=0 ,num;i<oldStr.length ();i++) { num=1 ; while (i<oldStr.length ()-1 && oldStr[i]==oldStr[i+1 ]) { i++; num++; } newStr+=to_string (num)+oldStr[i]; } oldStr=newStr; } return oldStr; } };
Longest Common Prefix 找出字符串数组的共有前缀:
1 2 3 Input: ["flower" ,"flow" ,"flight" ] Output: "fl"
方法一
设置公共前缀str为第一个字符串。
再str与下一个进行对比,更新公共str。
直到对比完所有字符串。
如果发现str为空,直接退出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public : string longestCommonPrefix (vector<string>& strs) { if (strs.size ()==0 ) return "" ; string str=strs[0 ]; for (int i=1 ;i<strs.size ();i++) { int j=0 ; while (j<str.length () && str[j]==strs[i][j]) { j++; } str=str.substr (0 , j); } return str; } };
方法二
先对数组进行长度的排序。
只对第一个和最后一个进行对比,找出公共部分即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution {public : string longestCommonPrefix (vector<string>& strs) { if (strs.size ()==0 ) return "" ; sort (strs.begin (), strs.end ()); int i=0 ; while (i<strs[0 ].length () && strs[0 ][i]==strs[strs.size ()-1 ][i]) { i++; } return strs[0 ].substr (0 ,i); } };
大数相乘 给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。
竖式运算思想,以 num1 为 123,num2 为 456 为例分析:
num2 除了第一位的其他位与 num1 运算的结果需要 补 0
计算字符串数字累加其实就是字符串相加
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 class Solution { string multiply (string num1, string num2) { if (num1 == "0" || num2 == "0" ) { return "0" ; } string res = "0" ; for (int i = num2. size () - 1 ; i >= 0 ; i--) { int carry = 0 ; string temp; for (int j = 0 ; j < num2. size () - 1 - i; j++) { temp.push_back ('0' ); } int n2 = num2[i] - '0' ; for (int j = num1. size () - 1 ; j >= 0 || carry != 0 ; j--) { int n1 = j < 0 ? 0 : num1[j] - '0' ; int product = (n1 * n2 + carry) % 10 ; temp.append (std::to_string (product)); carry = (n1 * n2 + carry) / 10 ; } reverse (temp.begin (), temp.end ()); res = addStrings (res, temp); } return res; } string addStrings (string num1, string num2) { string builder; int carry = 0 ; for (int i = num1.l ength() - 1 , j = num2.l ength() - 1 ; i >= 0 || j >= 0 || carry != 0 ; i--, j--) { int x = i < 0 ? 0 : num1[i] - '0' ; int y = j < 0 ? 0 : num2[j] - '0' ; int sum = (x + y + carry) % 10 ; builder.append (std::to_string (sum)); carry = (x + y + carry) / 10 ; } reverse (builder.begin (), builder.end ()); return builder; } }
数字字符串转化成IP地址 现在有一个只包含数字的字符串,将该字符串转化成IP地址的形式,返回所有可能的情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution {public : vector<string> restoreIpAddresses (string s) { vector<string> result; string t; DFS (result, t, s, 0 ); return result; } void DFS (vector<string> &result, string t, string s, int count) { if (count==3 && isValid (s)) { result.push_back (t+s); return ; } for (int i=1 ; i<4 && i<s.size (); i++) { string sub = s.substr (0 ,i); if (isValid (sub)) DFS (result, t+sub+'.' , s.substr (i),count+1 ); } } bool isValid (string &s) { stringstream ss (s) ; int num; ss>>num; if (s.size ()>1 ) return s[0 ]!='0' && num>=0 && num<=255 ; return num>=0 && num<=255 ; } };
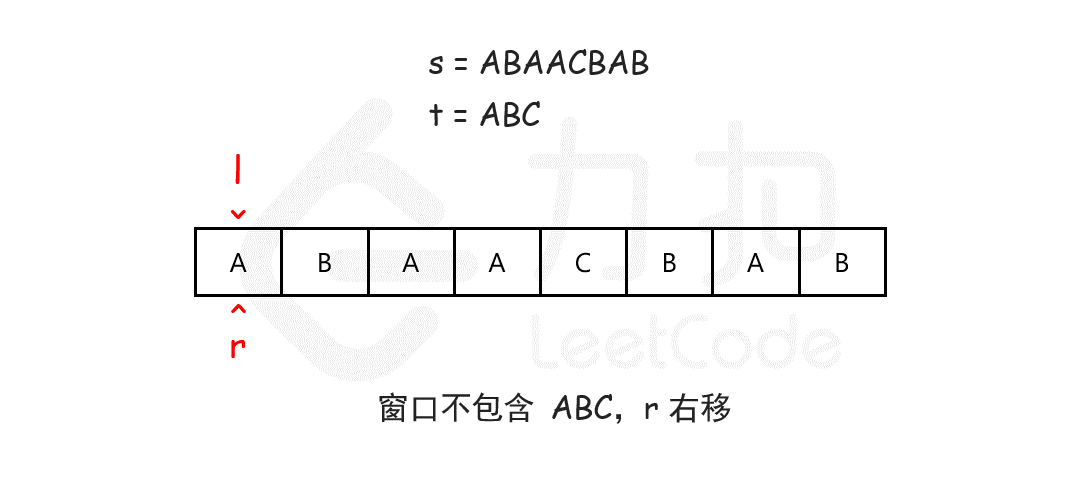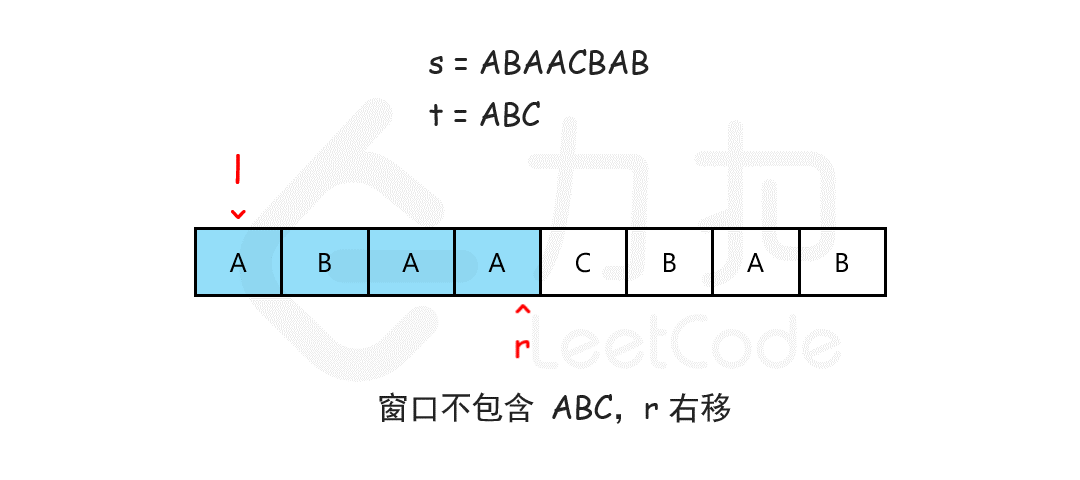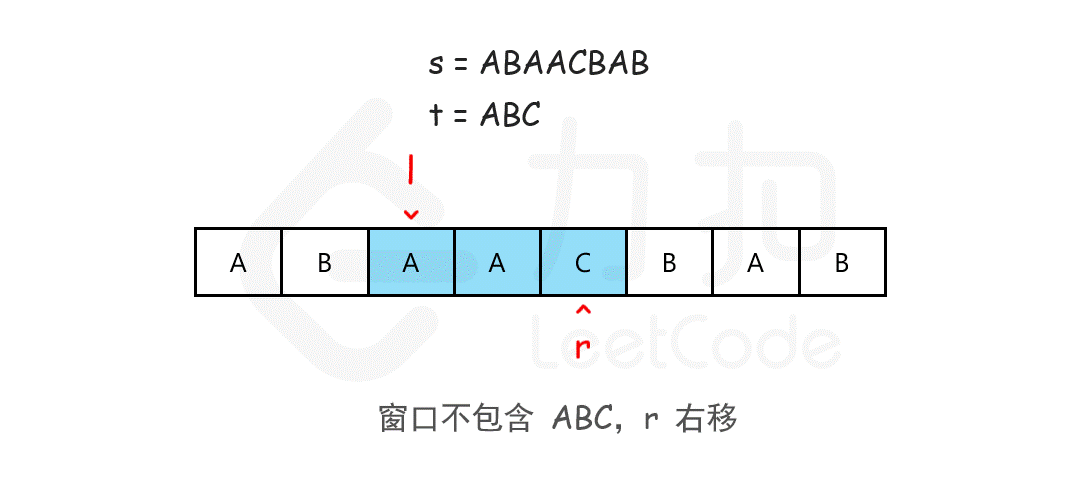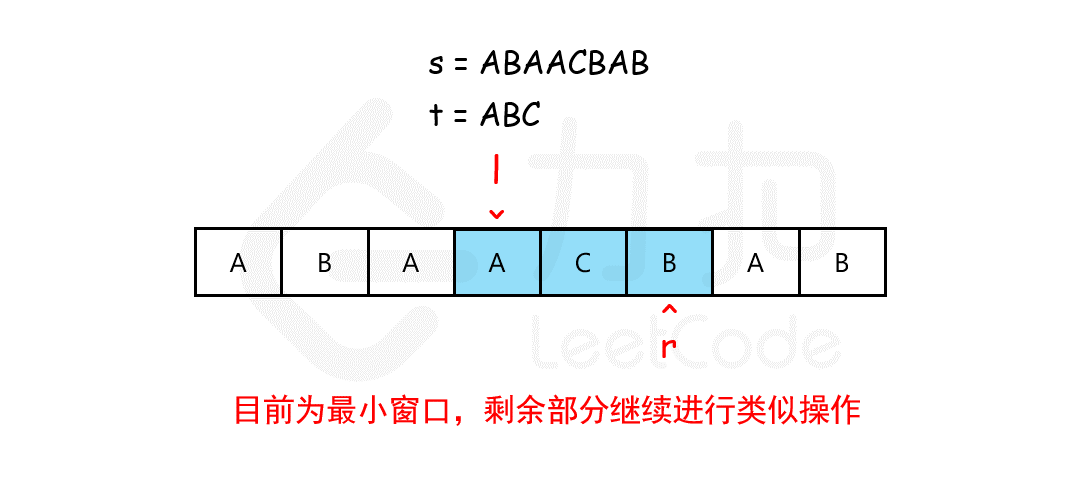
最小覆盖子串 给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 “” 。
输入:s = “ADOBECODEBANC”, t = “ABC”
我们可以用滑动窗口的思想解决这个问题。在滑动窗口类型的问题中都会有两个指针,一个用于「延伸」现有窗口的 rrr 指针,和一个用于「收缩」窗口的 lll 指针。在任意时刻,只有一个指针运动,而另一个保持静止。我们在 sss 上滑动窗口,通过移动 rrr 指针不断扩张窗口。当窗口包含 ttt 全部所需的字符后,如果能收缩,我们就收缩窗口直到得到最小窗口。
如何判断当前的窗口包含所有 ttt 所需的字符呢?我们可以用一个哈希表表示 ttt 中所有的字符以及它们的个数,用一个哈希表动态维护窗口中所有的字符以及它们的个数,如果这个动态表中包含 ttt 的哈希表中的所有字符,并且对应的个数都不小于 ttt 的哈希表中各个字符的个数,那么当前的窗口是「可行」的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 string minWindow (string s, string t) { unordered_map<char , int > need; int need_cnt = t.size (); int min_begin = 0 , min_len = 0 ; for (const char & c : t) { need[c]++; } for (int left = 0 , right = 0 ; right < s.size (); ++right) { if (need[s[right]] > 0 ) { need_cnt--; } need[s[right]]--; if (need_cnt == 0 ) { while (need[s[left]] < 0 ) { need[s[left]]++; left++; } int len = right - left + 1 ; if (min_len == 0 || len < min_len) { min_begin = left; min_len = len; } need[s[left]]++; need_cnt++; left++; } } return s.substr (min_begin, min_len); }