分布式锁和数据库锁
分布式锁
多个服务竞争稀缺资源,需要使用分布式锁。
- 锁是一种资源,需要存储,高可用性,避免锁全局失效。
- 隐含条件:加锁和释放锁必须是同一个对象,需要记录持有锁的对象。
- 另外需要实现互斥的语义,获取锁做个标记,释放锁时取消标记。
- 获取锁和释放锁都是网络通信实现的,需要考虑锁超时的问题。
- 锁释放通知问题:a.定时探寻。b. 被动通知(包括广播,和通知能够获取锁的特例)
- 是否允许同一个对象多次获取锁,可重入锁
特性:互斥性、可重入性、锁超时(取到锁的进程可能会宕机)、高可用性(redis集群实现,哨兵模式和cluster模式都是异步复制、最终一致性,可能会丢数据,cluster集群lua脚本可能失效)、分类(公平锁:根据队列顺序获取锁、非公平锁:随机派发锁)
其中高可用可分为计算型和存储型,计算型的是无状态的,存储型需要有一致性的协议,主要包括选举主节点、数据复制。
实现方式:redis/mysql、zookeeper/etcd
setnx ‘lock’ 1 // 获取锁,如果key不存在,才能设置成功
set ‘lock’ nx px 100 // 100ms后自动删除,设置超时
分布式锁是由哪个服务获取的?set ‘lock’ 唯一标识
- sip/sport:cip/cport唯一标识一个进程,加上starttime:pid
- 雪花算法,生成一个的 64 位比特位的 long 类型的唯一 id,最高 1 位固定值 0,因为生成的 id 是正整数,如果是 1 就是负数了。接下来 41 位存储毫秒级时间戳,2^41/(1000606024365)=69,大概可以使用 69 年。再接下 10 位存储机器码,包括 5 位 datacenterId 和 5 位 workerId。最多可以部署 2^10=1024 台机器。最后 12 位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成 2^12=4096 个不重复 id。可以将雪花算法作为一个单独的服务进行部署,然后需要全局唯一 id 的系统,请求雪花算法服务获取 id 即可。

CAP理论:
一致性(最终一致性、强一致性),可用性(在合理的时间内,返回合理的回复),分区容错性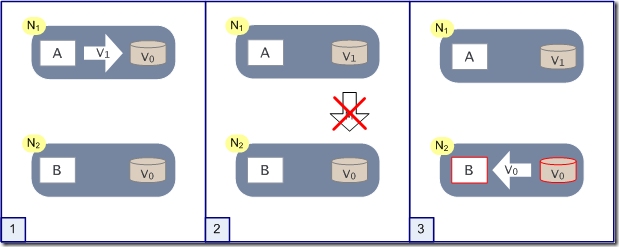
假设在N1和N2之间网络断开的时候,有用户向N1发送数据更新请求,那N1中的数据V0将被更新为V1,由于网络是断开的,所以分布式系统同步操作M,所以N2中的数据依旧是V0;这个时候,有用户向N2发送数据读取请求,由于数据还没有进行同步,应用程序没办法立即给用户返回最新的数据V1,怎么办呢?
有二种选择,第一,牺牲数据一致性,响应旧的数据V0给用户;第二,牺牲可用性,阻塞等待,直到网络连接恢复,数据更新操作M完成之后,再给用户响应最新的数据V1。
这个过程,证明了要满足分区容错性的分布式系统,只能在一致性和可用性两者中,选择其中一个。
- CP without A:如果不要求A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。
- AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
为什么zookeeper是CP?zk的数据结构?
在Zookeeper中,一致性是最重要的因素。Zookeeper使用了ZAB(Zookeeper Atomic Broadcast)算法来确保强一致性。在ZAB算法中,Zookeeper通过对于恰好一半以上的节点的广播来保证数据的一致性,而这需要半数以上的节点保持连通才能确保数据的完整性。如果Zookeeper为了保证可用性出现了不一致情况,就会对整个分布式系统产生影响,因此Zookeeper默认优先保证一致性而不是可用性。
数据存储的根本是基于一个被称为Znode的数据结构。每个Znode都是一个类似于Unix文件系统的节点,它们可以包含数据、子节点、元数据等。Znodes的结构类似于树形结构,并且每个Znode节点具有一个版本号,因此可以精确地跟踪它们是否已经更改。此外,Zookeeper还提供了监视器和临时节点等功能,这些能力为开发者提供了更高级别的数据操作和协调支持。
数据库锁
解决事务的隔离性。事务解决了数据库从一个一致性的状态到另外一个一致性的状态。
事务acid特性:
- 原子性:要么全部执行(多个步骤,多个用户操作),要么回退到最开始的状态,undo log逻辑表
1 | update table set a = a + 1 where id = 11; |
- 隔离性:多个用户之间锁来实现,问题:脏读(读到了未提交的数据)、不可重复读(事务 A 多次读取同一数据,但事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致)、幻读(select 某记录是否存在,不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读),不可重复读侧重表达 读-读,幻读则是说 读-写,用写来证实读的是鬼影。隔离级别:read uncommitted(三个问题都没有解决)、read committed(解决了脏读)、repeatable read(解决了不可重复读,需要手动解决幻读)、serializable,其中可重复读是 MySQL 默认的事务隔离级别
- 持久性:事务要持久化,redo log物理表
- 一致性:由另外三个特性提供保证
mysql innodb锁的实现,select网络模型,多线程并发处理连接。
1 | while (true) { // 单个连接 |
分布式两阶段提交协议(Distributed Two-Phase Commit Protocol)是一种用于在分布式系统中实现事务的协议。
简单介绍两阶段提交协议的过程:
- 准备阶段:
系统协调者向参与者发出“准备提交”请求,参与者执行事务,并将Undo和Redo信息写入日志,但并不真正地提交事务。如果参与者完成了事务并准备好提交,则向系统协调者发送“同意提交”消息,否则回滚写日志。如果有一个参与者发生了错误,系统协调者向所有其他参与者发送“回滚”请求。 - 提交阶段:
如果所有参与者都已经同意提交,则系统协调者向所有参与者发出“提交”请求,参与者完成真正的提交,从而完成整个事务。如果有一个参与者发生错误,则系统协调者发送“回滚”请求,所有参与者回滚到事务执行前的状态。
优点:
两阶段提交协议在分布式系统中实现事务的时候,能够保证ACID属性(原子性、一致性、隔离性和持久性)的完整性和可靠性。
缺点:
由于两个步骤之间存在阻塞等待,所以当连接丢失、系统故障或网络故障等问题发生时,事务启动程序必须等待超时来处理。这就导致了DTP无法处理某些故障情况下的事务。在例如硬件故障导致倒塌,长余时不能确定事务处理的情况下,DTP相较于其他机制的性能较差。